

What is Apache Kafka?
And why do more than 80% of Fortune 100 companies use it?

Data Engineer at Media.Net | Sharing my learnings and experiences in tech.
1. What is Kafka?
• Kafka is an open-source, high performance and distributed platform for streaming data from one point to another.
• It acts as a message queue for streaming massive amounts of data.
2. How does it work?
• It uses a producer-consumer model to move data from one point to another with the help of a topic.
• Kafka guarantees that the order of receiving messages will be the same as the order in which they were sent.
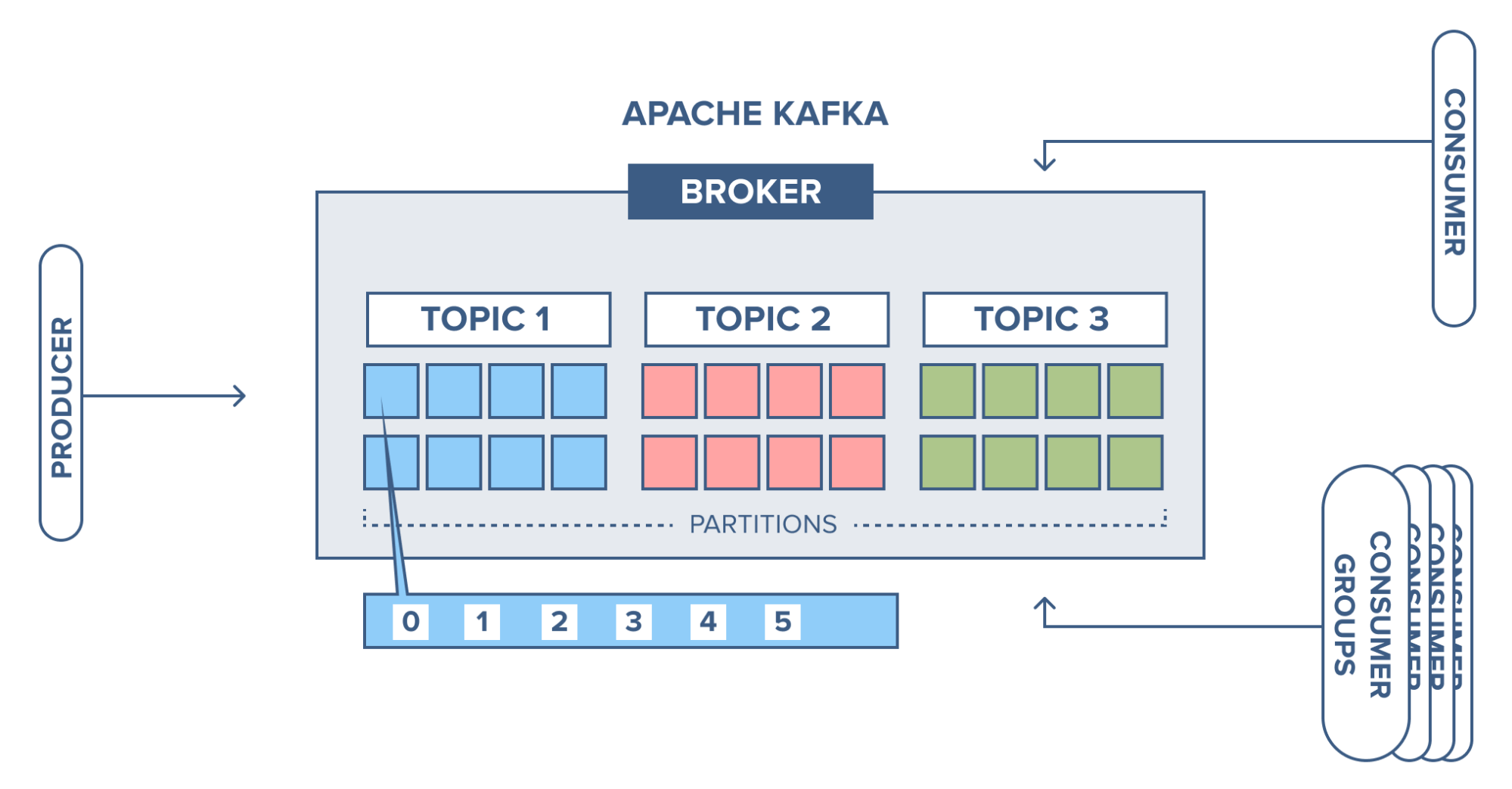
3. What is a topic?
• It stores data.
• It is similar to tables in databases but without constraints.
• It is identified by its name.
• Multiple producers can write to a single topic.
• Multiple consumers can consume from a single topic.
• It is split into partitions.
4. What are partitions?
• A topic is split into partitions.
• These partitions are on different Kafka Brokers i.e. Servers.
• This is necessary for scalability and fault-tolerance.
• Any message with the same key will go into the same partition inside a topic.
• Kafka guarantees the order of messages only within a partition.
• Data in a topic is kept for a limited time. (By default, for 7 days)
• Data written to partition can't change.
• A leader of partitions for a topic can send and receive data, others synchronize the data.
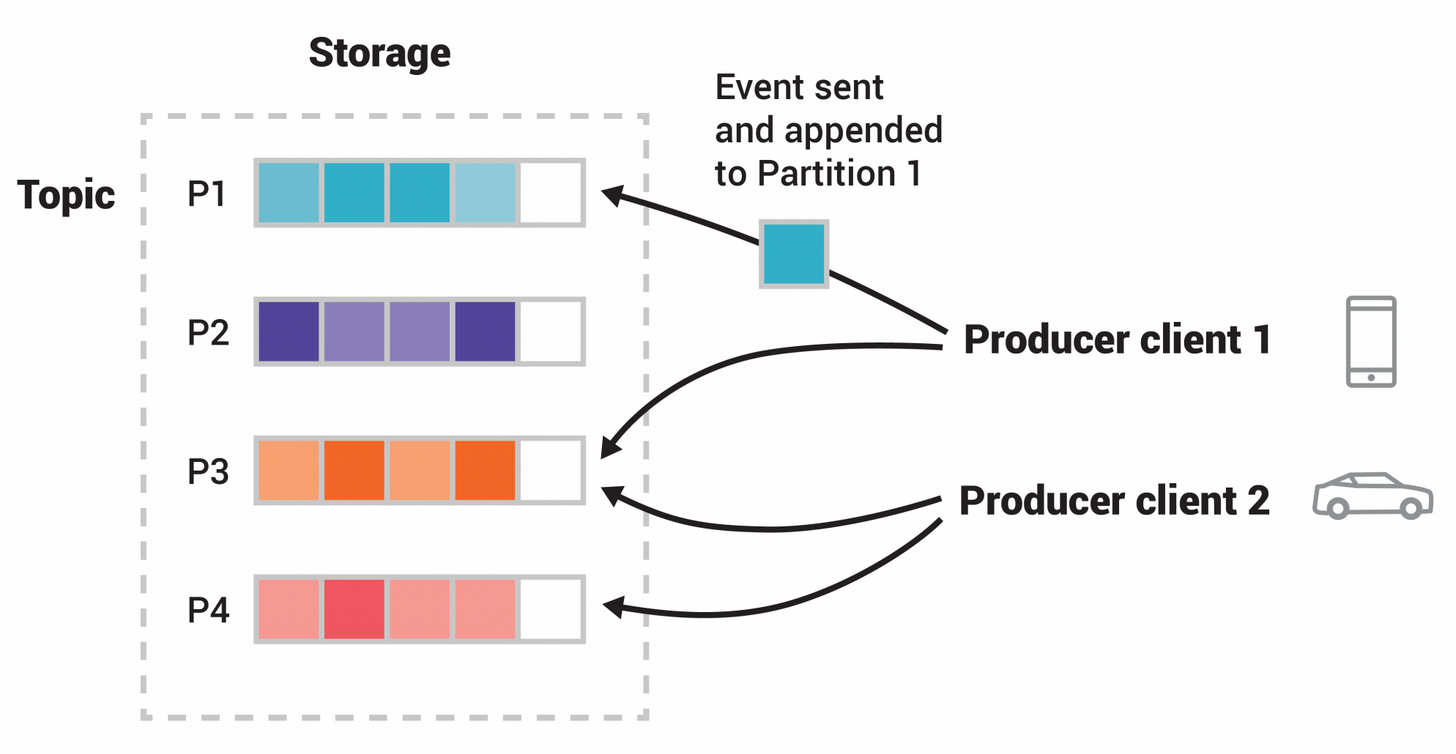
5. What are producers?
• These write data to a Kafka topic.
• To prevent data loss, there are 3 types of acknowledgement that producer can be configured for:
a) acks = 0: No acknowledgement. (Possibility for data loss)
b) acks = 1 (default): Producer waits for leader acknowledgement. (Limited data loss)
c) acks = all: Producer waits for leader and replicas acknowledgement. (No data loss)
6. What are consumers?
• It reads data from a Kafka topic.
• Data is read in order within each partition.
• There is a consumer group to which a consumer belongs.
• Each consumer within a group reads from exclusive partitions.
• A consumer must subscribe to a topic to consume data.
• If # of consumers > # of partitions, some consumers will remain inactive.
• In case of failures, Kafka provides 3 types of delivery semantics:
a) At most once: Data will be received at most once. Not more than that.
b) At least once: Data will be received at least once. It can be received more than once due to any failure. So keep this in mind.
c) Exactly once: Data will be received exactly once.
7. How does Kafka manage all of these?
• It uses Zookeeper.
• It helps in managing brokers.
• It helps in performing leader elections for partitions.
• It notifies Kafka of any changes. Eg. new topic, broker failure etc.
• It operates on an odd number of servers.
8. What are some core capabilities of Kafka?
• High Throughput.
• Scalable.
• Permanent Storage.
• High Availability.
Hence, because of all of these amazing features and a vast community of developers, Apache Kafka is the most widely used message queueing system.




